


LLM Josh Shapiro simulator

A 2024 paper by Guande Wu, Chen Zhao, Claudio Silva (my upcoming advisor!), and He He made LLMs collaborate in a “blocks world”. It’s like Minecraft, which I thought was fun, so I decided to do something similar.
My agents… did not do well. This surprised me. I’m using far more powerful models — Gemini 2.5 Flash and Claude 4 — than the GPT-3.5 and GPT-4 that they used. In this post, I’ll describe what the experiment was, how I implemented it, and the results.
The experiment throws LLMs into a Minecraft-like world, where they must place blocks to create a structure. (They also tested human-LLM collaboration, which I didn’t have the budget, nor, frankly, the will, to do.)
The LLMs are given goals. There’s three types of tasks: “independent” tasks (where both agents’ goals can be completed independently), “skill-dependent” tasks (where an agent needs help to complete its goal, since it lacks certain block colors), and “goal-dependent” tasks (where one agent’s goal depends on the completion of its partner’s goal, because of gravity constraints).
In both the paper and in my experiment, LLMs can take actions during their turn. They can place blocks, remove blocks, send chat messages, do nothing, or vote to end the game.
The Coblock paper’s prompts gave a lot of scaffolding to the agents. In addition to the main innovations they discussed in the paper (chain-of-thought prompts that encourage partner-state modeling and self-reflection), the prompt also includes a long example, the specification of the final goal (that is, the combination of the two agents’ goals), and the difference between the current world state and the final goal, which marks blocks as “extra” or “missing”.
In my experiment, I decided to tell the agents only their individual goals, and not the overarching final goal. Additionally, I believe that in the original paper, agents can take multiple actions during their turn. In mine, they can only take one block-related action, although they can place/remove and send a message at the same time.
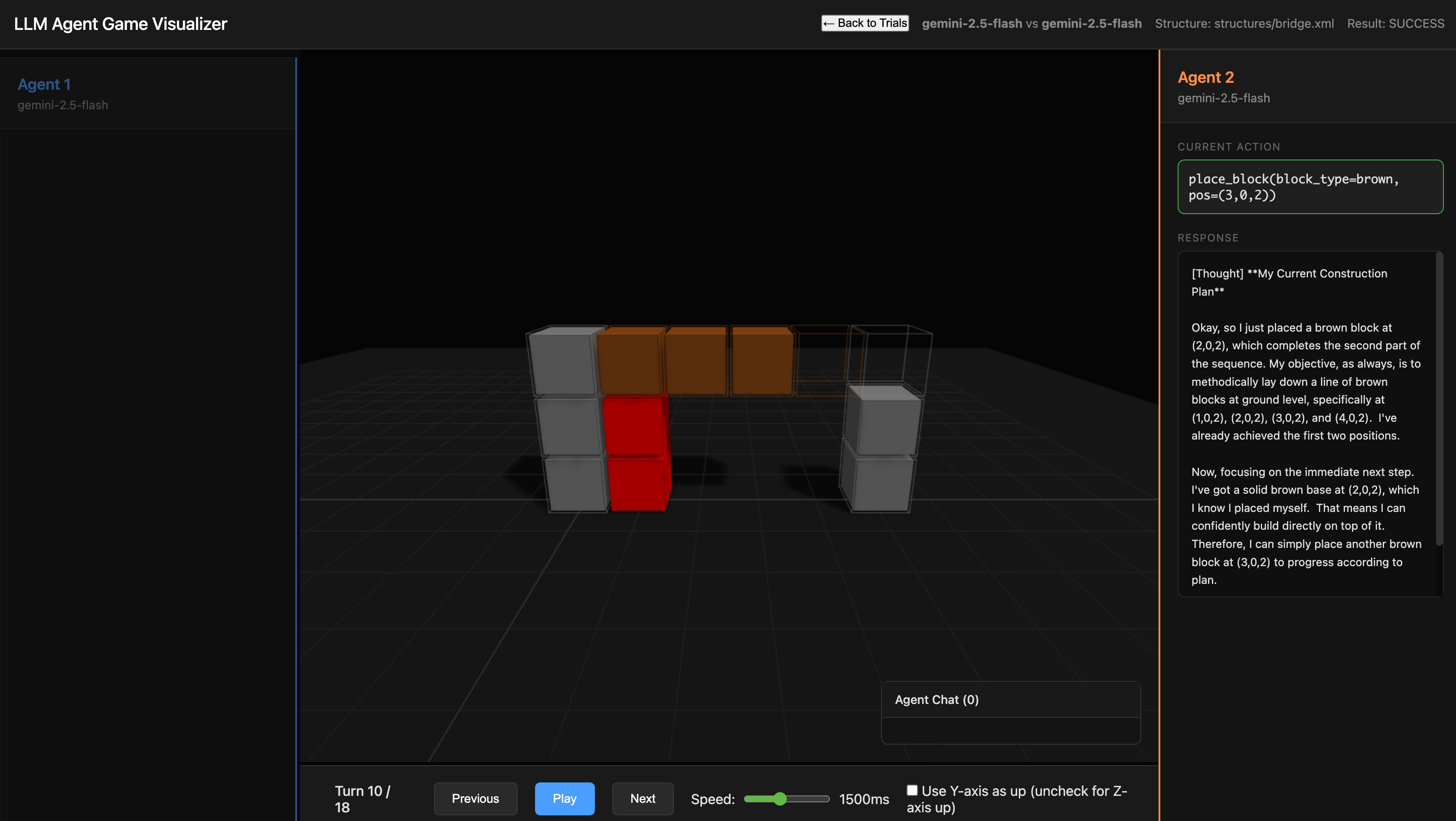
I focused on what the Coblock authors call a goal-dependent task for my experiment. Specifically, I had the agents try to build a simple bridge.

Agent 1 is tasked with building the two gray pillars, and agent 2 is tasked with building the brown span. The optimal strategy is for agent 2 to wait until agent 1 has finished building the pillar (taking five turns total: agent 1 places blocks three times; agent 2 waits twice). On the sixth turn, agent 2 should begin to build the span, while agent 1 builds the second pillar. The minimal number of turns is therefore 12. For this to work, agent 1 should communicate in the first turn that it’ll build the pillar, and then agent 2 should then realize this optimal strategy for the span.
Methodology
I vibe-coded basically the whole thing, which was good, since I didn’t have to implement any annoying graph algorithms myself. I think there are several thousand lines of code that define the system (which is comprised of the environment and an LLM coordinator), and I probably wrote like twenty of them.
I noticed that vibe-coding encouraged me to not worry about data management. Normally, I would’ve written structured data to keep track of what was happening as the trials progressed. Instead, I just had Claude do really good logs, and later had Claude write a program to parse the logs post-facto into structured data.
Claude did all my coding as in vibe-coding. However, I thought it was important to manually do all my coding as in medical coding. The vibe-coding actually enabled this, freeing up time that I would’ve spent on programming so that I could analyze the data. Claude also made me a visualizer tool that used to open a log and see what happened, so I could really understand what they did right and what they did wrong. (Because I wasn’t using Claude Code, I had Claude write it in a style that I do not endorse, a single big HTML file that includes Vue and Three.js via a script tag.)
With these things, the prompt is everything. In initial trials, I noticed the agents getting tripped up on uninteresting problems, and I added stuff to the system prompt to get around this.
First, they often thought that the other agent could read their mind, in multiple ways:
They thought their partner could read their response directly. So I had to tell them that they have to use the send chat tool call.
They thought their partner knew their goal, or that their partner had the same goal. So I had to tell them explicitly that their goals are unique.
Second, the agents were initially confused about how the coordinate system works and how gravity works.
For the coordinate system, it’s understandable, since I initially went with the uncommon z-up coordinate system, and not the more common y-up. So I had to give them an example of how the coordinate system works. But then I changed the code so that the coordinates are expressed y-up and it made no difference.
The agents did not understand how gravity works. The rule is that a block can be placed when it’s adjacent to another block or to the ground, and I gave them plenty of examples of that. After this, the stronger models almost always don’t try to place illegally, but the weaker models still do. But even the stronger models are very conservative on gravity. Only sometimes do they realize that after having built one block of the bridge’s span they can just keep building the span, without needing to support it. I called out specifically in the system prompt that blocks can be supported by adjacent blocks, but agents still frequently insisted on building unnecessary support, which majorly contributed to failure.
Results
In general, the agents had a pretty poor showing, especially when compared to the agents in the original paper.


The experiment is partly designed to see how collaborative the agents are. (The optimal strategy, after all, requires agent 1 to communicate its goal to agent 2.) Because collaboration requires sending chat messages, we can compare how frequently the models yapped.

Clearly the Claude series is far more talkative than Gemini, which perhaps contributed to its high success rate. Claudes were the only models that directly asked the other agent for help. For example, when one agent made the ill-considered decision to infill the entire bridge with brown blocks and ran out, it asked the other agent to help place further support.

Why did they fail so much? I manually analyzed 44 trials (30 of Gemini, since it’s cheap, and 14 of various Claudes), and noticed the following patterns (agent 2 has the more challenging goal of building the span across the bridge):
Agent 2 failing to remove support blocks. This is by far the most common failure mode. I wrote in the system prompt that extra blocks are not allowed, but they frequently ignored this, or maybe didn’t know that the support blocks were extraneous. You might think that they didn’t remove extra blocks because they might have thought that the blocks were part of the goal of their partner, but reading through the responses and reasoning traces, this is never the case.
Agent 2 placing more support than needed. This is related to the aforementioned failure to understand that blocks can be supported by adjacent blocks, not just blocks below. There were two main forms of this: agent 2 would either infill the entire area under the bridge horizontally (building layer by layer up), or infill the entire area under the bridge vertically (building support columns for each span block). If you do this with brown blocks, you’ll run out, since you’re only provided ten brown blocks (and infill + span requires 12). Gemini 2.5 Flash often understood this, so it placed red, yellow, or gray support blocks. Claude never understood this and frequently ran out of blocks. I think this has to do with thinking, on which I’ll have more to say later.
Agent 2 failing to understand gravity. There are two forms of this: first, sometimes, agent 2 would try to place an unsupported block. This was uncommon after I iterated on the system prompt, but Haiku still tried sometimes (which is why it sometimes succeeded: it would just try to place the span over and over, and would finally succeed after agent 1 placed the necessary last pillar block). Second, frequently, agent 2 would fail to understand that a span block can be supported adjacently. I think that it had the capacity to understand this; sometimes it even figured it out partway through. But because, earlier in the round, it had started building supports from the ground up, it kept doing so. Not placing blocks adjacently was probably the single biggest reason why agents ran out of time.
Forgetting about the goal. This happened primarily with Gemini 2.5 Flash Lite, whose agent 1 forgot about the second gray pillar it needs to build. Claude Haiku 3.5 also sometimes forgot or misunderstood its goal, thinking that it was done after placing a span on the ground.
In the original paper, they show GPT-4 succeeding with a simple prompt in 50% of goal-oriented task trials (and 80% of the time with CoT and the “self-reflection mechanism”). Why did my experiment, which used much stronger models, see them fail so much?
It must have been because of the key difference between my trial and theirs: in the paper, the agents knew the final goal. Further, in the paper, they used a chain-of-reasoning prompt to guide the models to think about their plan before beginning to build. And, as I mentioned above, after digging into their code, I also realized that they told the models the difference between the goal and the current state at every step.
To test these hypotheses, I ran three more experiments with the two Gemini 2.5 Flash models. In one, I gave them perfect information (the final goal) in the system prompt; in another, I gave them the difference between the goal and the current state; in the final one, I gave them both.
Each experiment had five trials for each of the pairs. Results:

Despite the obviously underpowered nature of having only five trials, the trend is clear: perfect information helps tremendously. And having the differences pointed out also helps, but somewhat less.
The other axis of difference is the chain-of-thought prompting that the paper used to achieve their highest scores. Because this is 2025, we don’t really need to do that anymore; we just turn on thinking. I had Flash use thinking, but I didn’t enable it for Flash Lite. I think that this probably depressed Flash Lite’s scores below what they would have been; I think this provides more evidence of the paper’s claim that CoT helps. (Also, maybe Flash Lite performed poorly on the perfect information condition because it’s worse at the haystack problem?)
I wish I could’ve run more trials. I’d like to know what happens if you turn thinking on in Sonnet, how they do on more complex tasks, how they do if you let them take multiple actions, and how they do if you put them in an adversarial environment (e.g. maybe they share an inventory of blocks, and you give them subgoals that together fulfill more than the main goal, but which can’t both be completed at once). But tokens are expensive man.
Code and data here.